








 Рейтинг: 4.7/5.0 (1646 проголосовавших)
Рейтинг: 4.7/5.0 (1646 проголосовавших)Категория: Инструкции
Re: Download Directories + PDFs from Website - HTTrack Website. * Aug 8, 2012. Subject: Re: Download Directories + PDFs from Website. Mirrored from %s%s by HTTrack Website Copier/3.x [XRCO#39;2010], %s --" -%l "en. HTTrack Website Copier - Offline Browser * HTTrack is an easy-to-use website mirror utility. It allows you to download a World Wide website from the Internet to a local directory,building recursively all. HTTrack Website Copier - Free download and software reviews. * Jul 31, 2014. HTTrack Website Copier goes to work very quickly from there, saving the information to a folder. While there is a file tree along the left side of. делаем локальную копию с помощью HTTrack Website Copier * 21 дек 2009. И тут нам на помощь приходит httrack website copier - это offline browser, который позволяет скачивать сайты целиком. В этом посте. PortableAppZ: HTTrack Website Copier 3.48-19 32-64 bit Multilingual * HTTrack Website Copier 3.48-19 32-64 bit Multilingual. Download Portable HTTrack Online (0.4 MB). Settings of installed HTTrack should be preserved.Как скачать весь сайт с помощью HTTrack Website Copier * Настройка проекта в программе HTTrack Website Copier. 6. Здесь мы. Я рад, что эта инструкция помогает скачивать целые сайты ). Ответить.Вопросы и ответы - Форум программы HTTrack Website Copier * Иконка HTTrack Website Copier 3.48-19. Есть вопросы по программе HTTrack Website Copier. Инструкция по установке программ для новичков. Download HTTrack Website Copier 3.44-1 - install httrack-website. * Download HTTrack Website Copier for Windows 7 for free - Website Copier/ Offline Browser. Copy websites to your computer. Open Source.WinHTTrack. Программа для скачивания сайтов целиком. * Появится следующее окно, в котором оставляем галочку на Launch WinHTTrack Website Copier, если хотим запустить программу сразу же после. HTTrack Website Copier - Free Software Offline Browser (GNU GPL) * HTTrack is a free (GPL, libre/free software) and easy-to-use offline browser utility. It allows you to download a World Wide Web site from the Internet to a local. HTTrack Website Copier * On this tab you can find tips and tricks for HTTrack Website Copier and detailed video tutorials for concrete solutions to HTTrack Website Copier 3.48-19.Httrack Users Guide (3.10) * HTTrack Website Copier. This sort of a mirror image is not an identical copy of the original web site - in some ways it#39;s better such as for local use - while in. History: bug fixes, new features - HTTrack Website Copier - Free. * HTTrack is a free (GPL, libre/free software) and easy-to-use offline browser utility. It allows you to download a World Wide Web site from the Internet to a local. HTTrack Website Copier 3.47.21: закачка сайта на жесткий диск. * 8 июл 2013. Несмотря на то, что HTTrack Website Copier имеет много настроек, эта утилита проста в обращении и не вызовет трудностей даже у. Marco Polo | Как слить сайт себе на компьютер |HTTrack Website. * 27 мар 2014. Ваши пожелания и идеи оставляем здесь: http://vk.com/topic- 66471753_29869516. Название программы: HTTrack Website Copier. HTTPS form-based authentication - HTTrack Website Copier Forum * Sep 24, 2012. Hello, Is HTTrack form-based authentication working with HTTPS? I have been unsuccessful at using "URL Capture" in that context. I tried to. Uninstall WinHTTrack Website Copier -2 - Howto Removal * Step2: Launch Special Uninstaller, locate WinHTTrack Website Copier -2 on the program list of Special Uninstaller, select it, and click "Run Uninstaller" button.Как скачать сайт целиком в HTTrack Website Copier - Сеть и. * 31 окт 2011. Рассматриваемая в обзоре программа HTTrack Website Copier для загрузки сайта в наше время уже не настолько востребована, как. scripting examples using the httrack commandline program * Links are rebuiltrelatively so that you can freely browse to the local site (works with any. HTTrack Website Copier. HTTrack Programming page - scripting.WebHTTrack HTTrack Website Copier - Free Download - Tucows. * It lets you download Web sites to local directories, building recursively all directories, getting HTML, images, and other files from the server to your computer.
Скорость: 9333 Kb/s









Отключен JavaScript У вас отключен JavaScript. Некоторые возможности системы не будут работать. Пожалуйста, включите JavaScript для получения доступа ко всем функциям. На все вопросы связанные с созданием сайта задавайте в личку или в icq - отвечу только. Пробовал и Teleport Pro и WinHTTrack выдает ошибку. Может нуна еще настраивать как нибудь эти проги? У меня чего то вообще не получается закачать сайт. Пробовал и Teleport Pro и WinHTTrack выдает ошибку. Может нуна еще настраивать как нибудь эти проги? Что именно у Вас не получаеться, а настраивать особо ничего не. Пропишите в проге данные которые Вам пришли от хостинга при регистрации! Лично я пользуюсь прогой FileZila У меня чего то вообще не получается закачать сайт. Пробовал и Teleport Pro и WinHTTrack выдает ошибку. Может нуна еще настраивать как нибудь эти проги? С помощью Teleport Pro и WinHTTrack Вы делаете копию страниц продажников, а Вам что нужно файлы залить на хост. Кротов Андрей Коммерсант Киберсанты 301 сообщений Страна, Город: Челябинская обл. Троицк Пол: Мужчина Странно, я вот все выполнил, заменил ссылки,запустил, все работает, но цена клика НЕ ИЗМЕНИЛАСЬ. Может я чот не то сделал? Установил прогу HTTrack Website Copier, вставил ссылку продажника пробовал несколько вариантовв поле тип выбрал - загрузить сайты, жму далее и все, прога отказывается закачивать сайт мне на комп. Выскакивает окно с сообщением об ошибке: В логе программы пишет, что "Connect Error". Не могу понять чего. В браузере меню "файл" "сохранить как" "веб-страница, полностью", что еще надо? Потом в Dreamweaver дорабатываем. В браузере меню "файл" "сохранить как" "веб-страница, полностью", что еще надо? Потом в Dreamweaver дорабатываем. Ну на счёт этого я то знаютолько вот зачем весь этот мануал вначале страницы по скачиванию всего сайта. Ну на счёт этого я то знаютолько вот зачем весь этот мануал вначале страницы по скачиванию всего сайта. Чтобы жизнь медом не казалась! Установил прогу HTTrack Website Copier, вставил ссылку продажника пробовал несколько вариантовв поле тип выбрал - загрузить сайты, жму далее и все, прога отказывается закачивать сайт мне на комп. Выскакивает окно с сообщением об ошибке: В логе программы пишет, что "Connect Error". Не могу понять чего. Ну если "Connect Error" это же скорее всего с соединением, у Вас анлим ИНТЕРНЕТ? Попробуйте в поле "тип" ничего не вставлять да, Павел у меня безлимитный интернет ОГОи соединение у меня идет напрямую через модем, тоесть модем сам логинится и входит в инернет, на компе по удаленному доступу ничего не настраивается. А в поле тип не могу ничего не выбрать, там полюбому какой то пункт нужно выбрать. А в поле тип не могу ничего не выбрать, там полюбому какой то пункт нужно выбрать. Да нет я в этом поле ничего не выбираю Установил прогу HTTrack Website Copier, вставил ссылку продажника пробовал несколько вариантовв поле тип выбрал - загрузить сайты, жму далее и все, прога отказывается закачивать сайт мне на комп. Выскакивает окно с сообщением об ошибке: В логе программы пишет, что "Connect Error". Не могу понять чего. Все - желаю успеха Неа не катит, всё делаю точно так же, Black Vic, ошибочка "Connect Error" и всё. Видать прога не врубается как у меня идет удаленное оединение. Ну да ладно, фиг с. Неа не катит, всё делаю точно так же, Black Vic, ошибочка "Connect Error" и всё. Видать прога не врубается как у меня идет удаленное оединение. Ну да ладно, фиг с. Виноват всему оказался "безобидный" фаервол. У кого будет проблемы с закачкой сайта себе на комп, попробуйте отключить свой фаервол. Сделал копию продажника, залил на хостинг, поменял ссылку в рекламной компании Яндекс Директ, но цена не изменилась. Кротов Андрей Коммерсант Киберсанты 301 сообщений Страна, Город: Челябинская обл. Троицк Пол: Мужчина pyrel просил видео по созданию копии продажника, вот моё авторское видео по созданию и переносу копии продающего сайта на хостинг. Может быть кому пригодится.
Другие статьи на тему:
![]()
Copyright © 2006-2016
goldenvilka.ru
HTTrack Website Copier (WebHTTrack) — программа для скачивания сайтов. В Linux программа работает через браузер и позволяет скачивать сайты целиком. Имеет различные настройки и фильтры.
HTTrack предназначена для скачивания сайтов к себе на компьютер и просмотра их в автономном (offline) режиме. Программа автоматически переходит по ссылкам и скачивает полностью (или частично) веб-сайты в зависимости от настроек.
Помимо простого скачивания HTTrack поддерживает дозакачку сайтов, обновление существующих закачек до актуальных версий, тестирование линков (ссылок).
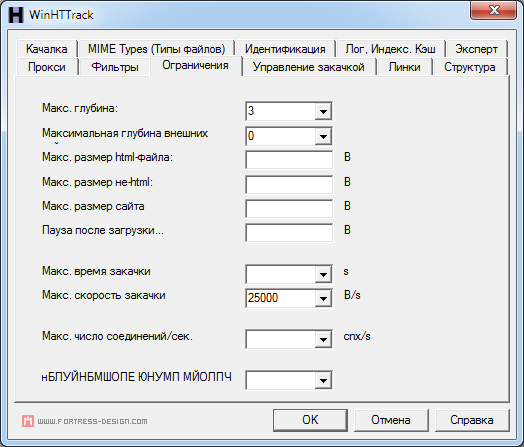
HTTrack позволяет скачивать сайты в несколько потоков, управлять скоростью загрузки, задавать глубину скачивания, фильтровать страницы и файлы по маске и выполнять множество других настроек.
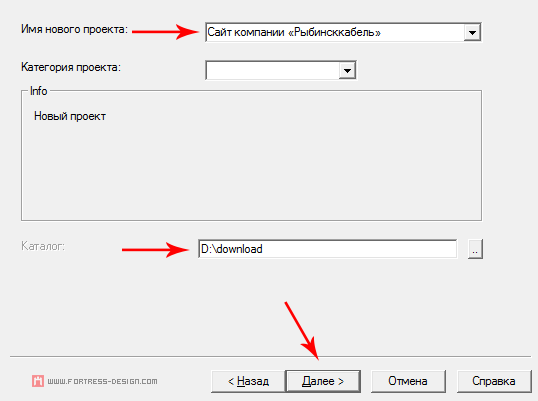
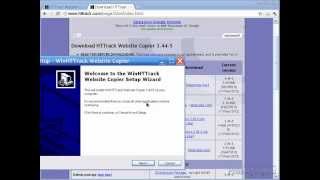
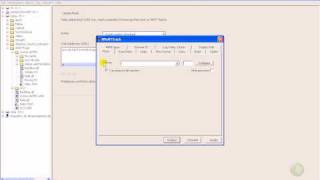
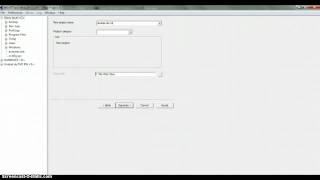
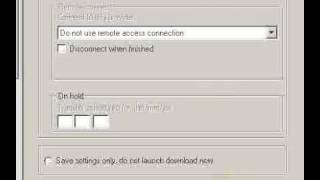
В Linux HTTrack работает через браузер как веб-приложение (WebHTTrack). Когда вы запускаете WebHTTrack, то автоматически открывается браузер и в нем запускается приложение. Сначала необходимо создать или выбрать существующий проект. Затем вы вводите один или несколько сайтов и указываете необходимые настройки (кнопка Задать параметры ).
Программа доступна для Linux, Windows, Android, а также доступны исходные коды для самостоятельной компиляции.
СкриншотыHTTrack: процесс загрузки сайта

HTTrack Website Copier 3.47.21 — это очень полезная программа с помощью которой Вы сможете скачать любой сайт целиком на свой жёсткий диск компьютера и впоследствии просматривать его без подключенного интернета.
При этом будет сохранена вся структура сайта, рубрики и страницы сайта со всеми ссылками и картинками…
Согласитесь, что очень удобно принести своим друзьям, у которых нет интернета, кусочек этого самого интернета на флешке, например.
Я уже описывал программу HTTrack Website Copier подробно, пошагово и в картинках на страницах этого сайта. Можете почитать и убедиться, что работать в ней сможет даже ребёнок.
Скачать самую актуальную версию HTTrack Website Copier Вы сможете с официального сайта производителей . где найдёте ссылки на любые версии программы (httrack-noinst — значит «портативная» ).

Создание копий веб-сайтов для их последующего просмотра.

HTTrackWebsite Copier - легкое в использовании приложение/оффлайн браузер для скачивания сайтов (консоль и web-интерфейс). для получения его точной копии с полной структурой подкаталогов и всеми файлами.

С помощью HTTrack Website Copier можно выкачать целый сайт с картинками и другими документами. Страницы сохраняются с относительной адресацией на другие страницы и документы.


HTTrack так же позволяет при загрузке перераспределить файлы, HTML страницы сохранять в одном каталоге, картинки и другие файлы в другом.

После окончания закачки на локальном диске пользователя создается идентичный сайт со всей внутренней структурой (можно назвать такую структуру "локальным зеркалом сайта") и возможен просмотр его, ссылка за ссылкой, так как будто он просматривается в интернете.

HTTrack отличается тем, что хорошо обрабатывает PHP и другие CGI-скрипты. т.е. динамически генерируемые страницы тоже будут закачиваться. Кроме того, HTTrack может отыскивать «зеркальные» сервера сайта.

HTTrack поддерживает докачку прерванных загрузок, а при необходимости позволяет обновить существующее локальное "зеркало сайта".

HTTrack полностью настраивается и имеет хорошую, встроенную справочную систему. Вся процедура работы, от настройки до окончания закачек, разбита на отдельные шаги и не вызовет трудностей даже у неопытного пользователя.






HTTrack Website Copier – Мощнейшая программа, позволяющая создавать копии интернет-страниц на жестком диске для последующего их просмотра.
Программа может возобновлять прерванные загрузки, создавать копии каталогов сайта, скачивать html-страницы, графические изображения и другие файлы. Кроме того, программа может отыскивать “зеркальные” сервера сайта. Несмотря на то, что HTTrack Website Copier имеет много настроек, эта утилита проста в обращении и не вызовет трудностей даже у неопытного пользователя.
HTTrack также может обновлять ранее скопированный сайт, и продолжать прерванные закачки. HTTrack полностью настраиваемый, имеет встроенную систему помощи.
HTTrack – бесплатный кроссплатформенный оффлайн браузер. Он позволяет загрузить сайт целиком в локальный каталог, построить структуру каталогов сайта, загрузить html, изображения и другие файлы из сети на локальный компьютер. HTTrack воспроизводит оригинальную относительную структуру ссылок сайта. Открыв страничку локального “зеркала” в браузере, можно перемещаться по ссылкам сайта, как будто вы находитесь в сети.
Хороший интернет-магазин приносит хорошую прибыль. В отличии от создания обычного сайта, создание интернет магазина имеет свои особенности, детали на этом ресурсе.
Видео HTTrack Website Copier:
How to use HTTrack Website Copier
Неправильная раскладка: реекфсл цуиышеу сщзшук 3.44-1 кгы + зщкефиду cjplfdfnm rjgbb bynthytn-cnhfybw
Транслитом: xттракк вебсите копиер 3.44-1 рус + портабле sozdavat kopii internet-stranic
На этой странице Вы узнали про: httrack website copier инструкция, инструкция HTTrack Website Copier, httrack website copier 3.44-1 rus, VEPSRE CJPLFDFNM CFQN, как сделать копию сайта в HTTrack Website Copier, httrack website copier инструкция настройки, httrack инструкция.
← НАЗАДАндрей Емелькин Ученик (241), закрыт 5 месяцев назад
При скачивании скорость максимум 30 Кб/с, конечно это достаточно для загрузки небольшого сайта, но она слишком маленькая для большого сайта вместе с файлами внутри него. ( При скачивании, например, торрента скорость намного более 200 Кб/с ).
Дополнен 5 месяцев назад
Может есть какие-нибудь плагины или расширения?
Дополнен 5 месяцев назад
С производительностью у меня всё отлично. Дело в программе, как у неё увеличить скорость скачивания? Она берёт намного меньше, чем есть.
Дополнен 5 месяцев назад
Xd no, между прочим, "инет" у меня более одного мегабайта в секунду.
Пауль Высший разум (1477530) 5 месяцев назад
Посмотрите раздел НАСТРОЙКА ПАРАМЕТРОВ в HTTrack Website Copier (winhttrack) – программа для скачивания сайта целиком. да и вообще, на открывшейся странице имеется множество полезных советов для этой программы.
Источник: удачных настроек!
Андрей Калишин Ученик (203) 5 месяцев назад
Есть программы для увеличения производительности, например, AVG PC Tune Up,скачай и проверь скорость установки какой-нибудь программы до и после. А вообще скорость загрузки увеличивает процесс, если возможно это сделать.
xd no Знаток (491) 5 месяцев назад
У тебя инет гавно
Андрей Емелькин Ученик (241) 5 месяцев назад
Имярек Такойто Мыслитель (7634) 5 месяцев назад
Выставь большее количество параллельных загрузок в программе,
отруби торренр-качалку,
перенеси место сохранения на RAM-диск,
проведи дефрагментацию HDD
и проверь, не нагружает ли его что-то,
а также можешь воспользоваться более качественной альтернативой - Offline Explorer.
Андрей Емелькин Ученик (241) 5 месяцев назад
А можете рассказать поподробнее? В настройках вроде нет регулирования количества параллельных загрузок.
MDM Мыслитель (5637) 5 месяцев назад
Сервер сайта не позволяет скачивать с большей скоростью. С торрента качаете в несколько потоков с разных адресов, а в вашем случает в один потом с одно адреса. Проблема не в программе!
af af Знаток (376) 5 месяцев назад
Хехехе, купи инет получше!
Фрекен Бонд Искусственный Интеллект (173766) 5 месяцев назад
инет расширить гигабайты
СветикСемицветик Мастер (1255) 5 месяцев назад
Архив блога можно сделать по-разному: например, экспортом в XML с помощью встроенной функции Blogger - но это для авторов. А если нужна работающая копия блога вместе с картинками, помещёнными на другом хостинге, простым wget -ом тут точно не обойтись. И тут нам на помощь приходит httrack website copier - это offline browser, который позволяет скачивать сайты целиком. В этом посте привожу небольшое руководство по httrack, в смысле как пользоваться httrack для зеркалирования блогов а-ля Blogspot.
Мои пять копеек, или Как скачать блог на blogger для локального просмотра
Так как с помощью wget (во всяком случае версии 1.10.2 ) создать полностью работоспособную копию блога на blogspot не получается, будем для этих целей использовать так же входящий в дистрибутив Debian (и не только его) offline броузер под названием httrack website copier. или просто httrack далее.
Насчёт wget - друзья, мне самому он очень нравится, но есть задачи, которые ему не по зубам. Без обид, всем теоретикам от WGET. ребята, прежде, чем делать глобальные выводы, ПОПРОБУЙТЕ СВОИ РЕЦЕПТЫ! Просто скачайте чей-нибудь мало-мальски нагруженный джаваскриптами и картинками на другом хостинге блог на blogspot с помощью wget. потом откройте его offline и Вы увидите большую разницу. Поверьте, это не так просто, и я на 100% солидарен с Андреем Афанасенко и его комментариями в обсуждении этой темы. всё не так просто. Опций, ключиков и шаманских проклятий к httrack море, но нам надо скачать блог - так что будем использовать и проверять опыт предыдущих поколений. Всё течёт и всё меняется, и на момент последней правки этого поста командная строка, которая позволяет зеркалировать для локального просмотра блог на blogspot выглядит так:
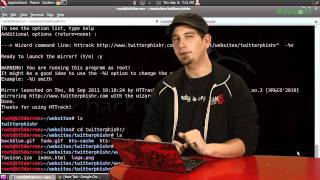
httrack "http:// ВАШБЛОГТУТ .blogspot.com/" "+*.css" "+*.js" "+*.jpg" "+*.jpeg" "+*.tiff" "+*.png" "+*.gif" "+*.giff" "+*.swf" "+.ico" -v --disable-security-limits -s0 "-*666*" "-*BlogBacklinkURL*" Кавычки обязательны. При этом хорошо бы сделать какой-нибудь каталог, в который вы будете это сваливать (например, /home/vasya/ ЗЕРКАЛОБЛОГА / ) и уже внутри этого каталога запускать httrack с вышеупомянутыми заклинаниями.
Во всяком случае для б логов на платформе блоггера эта формула работает. по крайней мере, так удалось полностью скачать блог IceWM and all around полностью, вместе с работающими ссылками на картинки (для просмотра в полный рост) и ссылками в метках, которые позволяют просмотреть все посты с одной меткой.
И ещё. Блоги некоторых особо злостных графоманов (вроде меня) занимают много, много места. так что запаситесь временем и местом на диске. Очень может быть, что сразу, за один раз, блог вытащить не удастся. Конкретно "Записки дебианщика" занимают вместе с картинками и комментариями почти 2Гб. Будучи сжатыми архиватором 7Z с агрессивными настройками, "записки" занимают 107Мб, но распакуются в те же 2Гб. Кстати скачать "Записки дебианщика" одним архивом теперь можно по этой ссылке .
Обновление локальной копии
Для того, чтобы продолжить скачивание большого блога или синхронизировать локальную версию с тем, что есть в Интернете, httrack может обновить скачанный проект. Насколько я понял, для этого нужно добавить к вышеупомянутому заклинанию ключик --update
То есть для обновления уже скачанного блога с blogspot из директории, где находится директория hts-cache (в ней лежит файл hts-cache/doit.log который содержит все нужные параметры) и пишем:
httrack "http:// ВАШБЛОГТУТ .blogspot.com/" "+*.css" "+*.js" "+*.jpg" "+*.jpeg" "+*.tiff" "+*.png" "+*.gif" "+*.giff" "+*.swf" "+.ico" -v --disable-security-limits -s0 "-*666*" "-*BlogBacklinkURL*" --update И httrack пытается обновить проект. И обновляет его, выкачивая оставшиеся файлы. Кстати, чтобы пропускать файлы со слишком тормозных серверов, можно ещё тайм-аут для httrack поставить поменьше, добавив ключик --timeout 20 после чего тайм-аут будет 20 секунд.
Отмечу так же, что в каталоге hts-cache лежат два больших архива в формате ZIP - так вот, удалить можно только тот из них, который называется old.zip, а new.zip лучше не трогать. Дело в том, что эти файлы содержат информацию, необходимую httrack для обновления скачанного сайта, и если эти файлы удалить, то вы не сможете просто обновить копию (придётся выкачивать всё заново).
Ссылки в тему
Над этой темой бились лучшие умы блоговедения и блоготехники, достижения коих увековечены к примеру в заметке Дмитрия Конищева Создание зеркала сайта и в посте Андрея Афанасенко Архив блога/blogarchive. За что оным умам (а так же всем, кто принимал участие в обсуждениях) низкий поклон и огромная благодарность.
Так же благодарность тов. vnaum за то, что разыскал в дебрях документации к Блоггеру ссылку на возможность получить все посты Blogger с помощью скриптов на Python.







![]()
Любопытненько. Передо мной задача зеркалирования блога не вставала, но задумка интересная. Попробую-ка свой скопировать ради интереса…
Придраться могу только к отсутствию ссылки вот здесь:
Кстати скачать "Записки дебианщика" одним архивом теперь можно по этой ссылке.
Спасибо, очень интересно и познавательно. Надо подумать как теперь это дело использовать для переноса с одного блога на другой (давно хотел перенести свой старый ЖЖ в блогспот, да руки все не доходили).
Хотел заметить, что получить архив своего блога проще всего из панели управления — Настройки/Основные сведения/Инструменты блога/Экспорт блога. И получаем XML со всем-всем-всем. Хороший XML. Только данные (но в том числе и все настройки-стили), никакого генерируемого HTML.
У меня была мысль, что можно написать скрипт, формирующий по этому XML-архиву документ TeX, вестаемый автоматически для чтения оффлайн — под печать или e-book. Вроде ljbook или blurb, но лучше :-) Дарю идею.
Ну и мои две копейки:
http://code.google.com/apis/blogger/docs/1.0/developers_guide_python.html#RetrievingWithoutQuery
(python-gdata в дебиане есть)
@ Programmaster пишет.
Любопытненько. Передо мной задача зеркалирования блога не вставала, но задумка интересная.
Скоро встанет такая задача и перед тобой, когда постов будет за сотню. Не всегда есть подключение к интернету - вон в МИФИ вторую неделю интернета нету. Хотя он уж и не МИФИ, я нияу. но не суть.
Придраться могу только к отсутствию ссылки вот здесь
Появилося :-)
P.S. А "синхронизовать" пропустил. Стареешь. Хе-хе-хе ;-)
@ Olly Cat пишет.
Надо подумать как теперь это дело использовать для переноса с одного блога на другой (давно хотел перенести свой старый ЖЖ в блогспот, да руки все не доходили).
Таким способом, думаю, вряд ли. Блогспот загружает один здоровенный XML-файл, но я без понятия, как его сформировать.
@ Сергей пишет.
Хотел заметить, что получить архив своего блога проще всего из панели управления — Настройки/Основные сведения/Инструменты блога/Экспорт блога. И получаем XML со всем-всем-всем.
О, а вот и оберфельдфебель Эвиденц в тред нагрянул. -)) Извини, Сергей, не смог удержаться ;-))
Хороший XML. Только данные (но в том числе и все настройки-стили), никакого генерируемого HTML.
Хорошая девочка Лида, а чем же она хороша. -)
Серьёзно, просмотреть его не получается. А раздавать этот файл всем - это у меня и так статьи тырят, а там просто двойники пойдут косяками.
У меня была мысль, что можно написать скрипт, формирующий по этому XML-архиву документ TeX, вестаемый автоматически для чтения оффлайн — под печать или e-book.
Ох ты ёлки-лампочки. Вот до чего хаскель-то доводит, мамочки, поди ж ты. -)
@vnaum пишет.
Ну и мои две копейки
Это целый рубль, vnaum! Спасибо!
P.S. Прошу простить за немного ироничные ответы, т.к. писал весь день отчёты. После этого сильно пробивает на посмеяться :-)
Всё бы тебе хиханьки да хаханьки. Отбираю дарёную идею обратно.
@ Сергей
Всё бы тебе хиханьки да хаханьки. Отбираю дарёную идею обратно.
Настроение весёлое было. В остальное время мрачный и занудный автор этих строк строчит унылые статьи в научные журналы и баянистые посты в блог :-)
Серьёзно. Сергей, насчёт идеи. Тамошний XML содержит только посты - без оформления и дважаскриптов. Распарсить его у меня не хватит духа, тем более перегнать в ЛаТеХ.
Скрипт "версия для печати" я как-то пытался пристроить, но неудачно.
Собственно, задача была такая, чтобы это локально читать - и httrack был единственный, кто с ней справился. Идея с XML-парсингом выглядит монументально, но мне её не потянуть. То есть всякие титанические проекты типа серия постов "Диплом в латехе" и "графики в гнуплоте" это пожалуйста, но с XML я пас. А за идею спасибо.
Тамошний XML содержит только посты - без оформления и дважаскриптов. Распарсить его у меня не хватит духа, тем более перегнать в ЛаТеХ.
Ну я не буду говорить, что это легко, но тамошний XML позволяет легко вытащить именно тексты постов. Если не ошибаюсь, это «почти HTML» (у меня — с пустыми строками вместо <p> и прочими поблажками). Толково написанный HTML в ЛаТэХ перегнать можно.
Кстати, вот попробовал. Взял HTML текста твоего поста, кроме подвала, пропустил через tidy и с помощью pandoc из sid сделал так:
$ pandoc -f html -t latex -s blogpost_.html | sed '2i\\\\usepackage\[T2A\]
$ pdflatex blogpost_.tex
В общем, ничего не делал, только русский fontenc добавил.
В общем, всё не так уж плохо. На практике, конечно, будут тонкости (например, конвертация gif-ов в png/jpg, выкачивание картинок высокого разрешения, обработка своих стилей, таблицы, наверное). Однако и так, на автомате, впечатляет.
Это я pandoc рекламирую, если кто не понял :-)
интересная заметка, может, мне и понадобится когда-нибудь! =)
// а не появится ли теперь у блоггеров новая "фаллометрия" -- чей блог больше весит?
Большое спасибо автору. я как раз на днях задумался над бекапом блога )))
вопрос не по теме. почему при нажатии на ссылки в МЕТКах ПОСТОВ(оффлайн версия блога) они не работают. а при открытие вместо названий кракозябы =( скачал несколько раз пробывал и всё время одно и тоже =(
Спасибо большое за статью, очень своевременно! Даже сделал к себе небольшую копипасту.
Воспользовался предложенным вами рецептом, порадовался неплохому результату, однако есть одно "но". В локальной копии не работает выборка сообщений по определённому тэгу, если это кириллический тэг. С тэгами на латинице всё работает "как надо", но кириллица в тэгах сохранилась на диск в кодировке cp-1252, и теперь Firefox говорит, что "не может найти файл /home/op/documents/02doc_notes/blogarchive/locke314.blogspot.com/search/label/?¿?¾?´N�?»N?N??°?½?¾.html."
Не подскажете, как бы эту неприятность обойти?
@Сергей, 23.12.2009 16:56:00
Ну я не буду говорить, что это легко, но тамошний XML позволяет легко вытащить именно тексты постов.
Серж, тексты постов у меня-то как раз есть :-) Однако в последнее время я обленился так, что обновлять их лень. Делаю экспорт блога и сохраняю в SVN.
Результат: blogpost_.pdf".
Вот это круто! Попробуем-с.
У меня тоже была мысль сделать что-то вроде хендбука для Дебиан (по мотивам наиболее часто забываемых мною вещей) и распечатать в свой ежедневник. На досуге (когда он у меня будет, интересно. -)) попробую сообразить что-то.
Это я pandoc рекламирую, если кто не понял :-)
Этот тонкий намёк я уловил, да :-))
@ Valdos the Fat Troll
а не появится ли теперь у блоггеров новая "фаллометрия" -- чей блог больше весит?
Не думаю. По крайней мере мне это точно не грозит :-)
@ AccessD, 27.12.2009 23:08:00
Большое спасибо автору. я как раз на днях задумался над бекапом блога )))
Пожалуйста, хотя это спасибо Андрею Афанасенко и Дмитрию Конищеву.
И потом, это не бекап блога, а только его локальная копия.
@ eshelon, 29.12.2009 15:17:00
вопрос не по теме. почему при нажатии на ссылки в МЕТКах ПОСТОВ(оффлайн версия блога) они не работают
Вопрос-то как раз по теме. Работают не все метки, что обидно. Причина этого выясняется.
@locke314, 01.01.2010 22:05:00
Воспользовался предложенным вами рецептом, порадовался неплохому результату, однако есть одно "но". В локальной копии не работает выборка сообщений по определённому тэгу, если это кириллический тэг.
Есть такое НО. Я попробую связаться с авторами и это дело прояснить. Там как обычно - для латинницы работает, с кириллицей всё веселее. Причём работают короткие теги (у меня примерно половина нормально открывается).
Не подскажете, как бы эту неприятность обойти?
Пока не знаю сам, как это обойти. Но постараюсь выяснить. Оставайтесь на этой волне - пост может обновиться на эту тему.
Спасибо! Как раз то, что нужно было ))
Спасибо. Скоро пригодится. Полезная статья.
Отправить комментарий







